Mozilla Releases Open Source Speech Recognition Engine and Voice Dataset
After launching Firefox Quantum, Mozilla continues its upward trend and releases its Open Source Speech Recognition Model and Voice Dataset. Well, Mozilla is finally back!
In the past few years, technical advancements have contributed to a rapid evolution of speech interfaces and, subsequently, of speech-enabled devices powered by machine learning technologies. And thanks to Mozilla’s latest efforts, things look better than ever.
Speech recognition is the key to the next generation user interfaces and user experiences. While speech alone won’t fit any scenarios, in many cases speech is a better interaction method than typing or clicking buttons.

Speech recognition engines are now sufficiently mature to allow developers to integrate them into their apps. However, speech recognition (speech to text) is only part of the equation. The other side of the equation, the one that enables an app to interact naturally with the user, is text-to-speech. And here is where Mozilla comes in hard.
Mozilla DeepSpeech Speech Recognition
“There are only a few commercial quality speech recognition services available, dominated by a small number of large companies. This reduces user choice and available features for startups, researchers or even larger companies that want to speech-enable their products and services …” // Sean White @Mozilla Blogs
No-Code Email Template BuilderWith Postcards Email Builder you can create and edit email templates online without any coding skills! Includes more than 100 components to help you create custom emails templates faster than ever before.
Free Email BuilderFree Email Templates
While there are several open-source acoustic models available to developers, none of them is as impressive as Mozilla’s project. On the other hand, closed source projects, while significantly more advanced than their open-source counterparts, are either unavailable to developers and researchers or are prohibitively expensive.
On top of that, implementing different APIs may be time-consuming and inefficient for many developers. This significantly reduces the impact of these technologies and subsequently, hinders innovation.
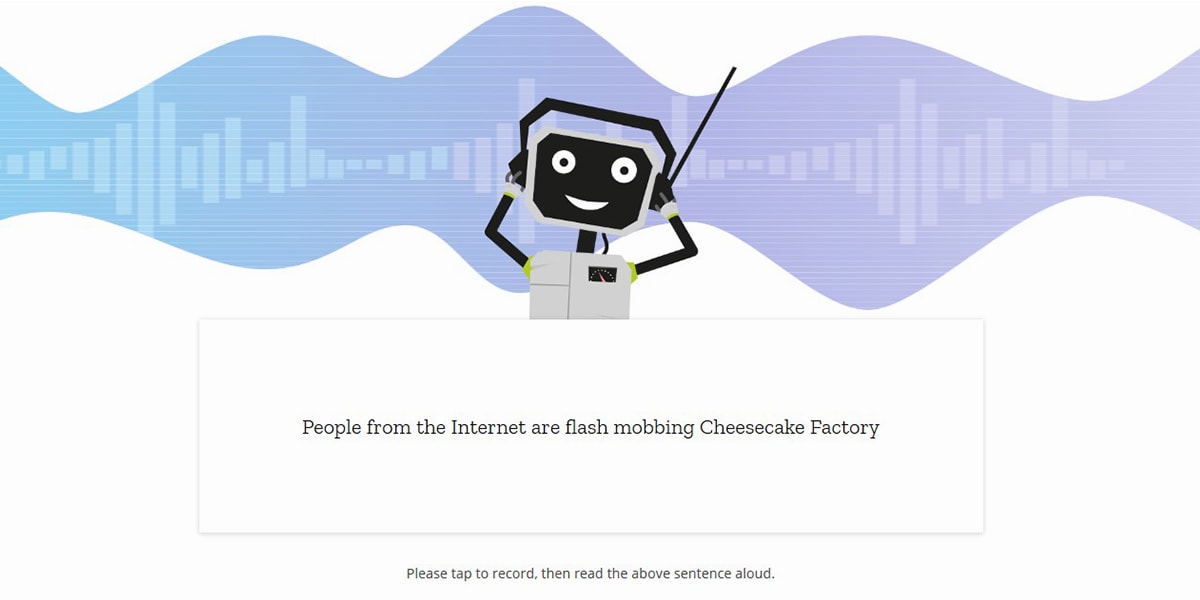
Another option is to purchase access to non-browser-based APIs, for example from Nuance or IBM. Unfortunately, for non-commercial projects, start-ups or research hubs, a “cent per invocation” price-model is unsustainable. By contrast, any developer comfortable with Python, NodeJS can use Mozilla’s engine to experiment with speech recognition.
Mozilla’s DeepSpeech is an open source speech-to-text engine, developed by a massive community of developers, companies and researchers. The engine is built on Baidu’s “Deep Speech” research on trainable multi-layered deep neural networks.
With an error rate of just 6.5%, on LibriSpeech’s test-clean dataset Mozilla’s speech recognition model has a level of accuracy that is close to what humans perceive in similar tests.
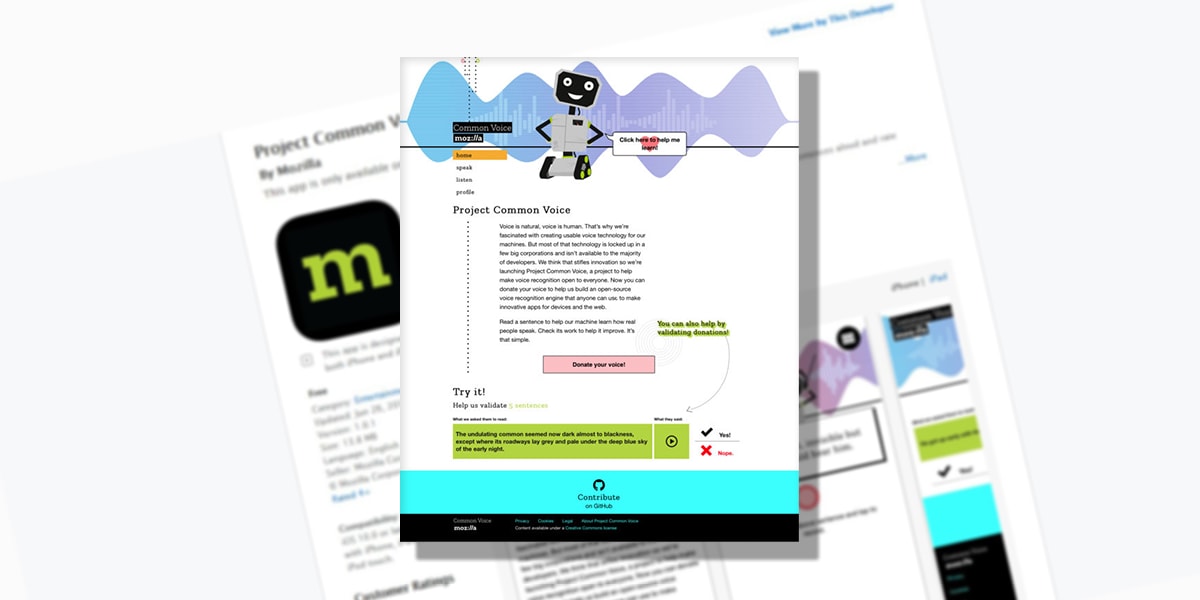
Common Voice, Mozilla’s Voice Dataset
Another problem that stalls research and the development of voice-enabled technologies is the lack of high quality, transcribed voice data sets.
With Startup App and Slides App you can build unlimited websites using the online website editor which includes ready-made designed and coded elements, templates and themes.
Try Startup App Try Slides AppOther ProductsProject Common Voice is building a voice dataset that everyone can use to train new voice-enabled applications. Currently, there are nearly 400,000 recordings, totaling more 500 hours of speech and contribution from more than 20.000 people globally. Anyone can download this data, and anyone can contribute. Yep, that’s precisely the open-source spirit.
“When we look at today’s voice ecosystem, we see many developers, makers, startups, and researchers who want to experiment with and build voice-enabled technologies. But most of us only have access to fairly limited collection of voice data; an essential component for creating high-quality speech recognition engines. This voice data can cost upwards of tens of thousands of dollars. ” // Michael Henretty @Medium
Current speech recognition algorithms are trained on artificial datasets, obtained in laboratory environments. These datasets are not representative of the world around us. By contrast, Mozilla’s data set is based on contributions from more than 20,000 people, reflecting a diversity of voices. Even more, beginning with the first half of 2018 the Common Voice project will support voice donations in multiple languages.
Open-Sourcing for the Future
Mozilla is committed to an open and accessible technology ecosystem. In a connected world where we are quickly switching from 2D to 3D, through new means like VR, AR and speech, the proprietary mindset won’t be enough to sustain our needs. Our future depends on how well we harness knowledge and gear it into inclusive and innovative technologies, open and accessible to all.
Think about the awesome things we can do thanks to Mozilla’s open source efforts. Speech recognition technologies are not only about entertainment or shopping but also about science and humanity. For example, think about how you could improve assistive technologies, so that we won’t have to leave people with disabilities alone. It’s all about sharing and gaining knowledge. Thank you, Mozilla!